采用何种方式进行内存分配取决于堆内存的规整性;而堆内存的规整性取决于虚拟机采用的垃圾回收算法是否带有压缩整理功能决定的。因此在使用Serial,ParNew等带Compact过程的垃圾回收器,虚拟机内存分配采用bump the pointer;而在使用CMS这种基于Mark-Sweep算法的垃圾回收器时,通常采用空闲列表这种方式。
b. 除了以何种方式从堆内存空间分配空间以外,还存在另一个线程安全的问题;当多个线程申请内存分配的时候,可能虚拟机正在使用内存指针给线程A分配内存的时候,线程B用采用原来的内存指针来进行内存分配了。这是典型的多线程问题,解决方法有两种:
对分配内存空间进行同步处理,保证分配操作是线程安全的、原子性的;实际上虚拟机采用的是WCAS(Compare and Set)配上失败重试的方法保证指针更新操作的原子性;
线程封闭的方式;把内存分配的动作按照线程划分在不同的空间中进行,即每个线程在堆中预先分配一小块内存称为本地线程分配缓冲(Thread Local Allocation Buffer TLAB)。哪个线程需要分配内存,就在对应的TLAB上分配,只有TLAB用完并分配新的TLAB的时候,才需要同步锁定。同步需要额外的花销。
运行时常量池是方法区的一部分。Class文件里面除了包含类版本、字段、方法、接口等描述信息外,还有一项就是常量表(符号表 constant pool table),用于存放编译时期(源码到字节码)产生的各种字面量和符号引用,例如 public int a = 2中的a,这部分内容在类加载后会进入方法区的运行时常量池。 运行时常量池相对于class文件的常量表的区别:
while ((sC = ssc.accept()) == null) System.out.println("i am pooling for new connection!");// poll until new connection was established.non-blocking sC.configureBlocking(false);
ByteBufferbuffer= ByteBuffer.allocate(1024); while (true) {//pool for reading intr= sC.read(buffer);//non-blocking System.out.println("i am pooling for new data!"); if (r > 0) { buffer.flip(); System.err.println("recv " + r +" bytes from " + sC); System.err.print(decoder.decode(buffer)); buffer.compact(); } }
Returns the runtime class of this Object. The returned Class object is the object that is locked by static synchronized methods of the represented class.
The returned Class object is the object that is locked by static synchronized methods of the represented class 这句话的意思是在说明一个事实:
LCS通常是指Longest Common Subsequence, 但是也可代指Longest Common Substring。子串是一种特殊的子序列,子串和子序列的区别就是字串要求是组成子串的 各字符是连续的,而子序列仅仅要求各字符的下标是递增的即可。举个例子,如helloworld, world是子串(也是子序列), hw不是子串是子序列。
/** * Returns an instance of a proxy class for the specified interfaces * that dispatches method invocations to the specified invocation * handler. This method is equivalent to: * <pre> * Proxy.getProxyClass(loader, interfaces). * getConstructor(new Class[] { InvocationHandler.class }). * newInstance(new Object[] { handler }); * </pre> * * <p>{@code Proxy.newProxyInstance} throws * {@code IllegalArgumentException} for the same reasons that * {@code Proxy.getProxyClass} does. * * @param loader the class loader to define the proxy class * @param interfaces the list of interfaces for the proxy class * to implement * @param h the invocation handler to dispatch method invocations to * @return a proxy instance with the specified invocation handler of a * proxy class that is defined by the specified class loader * and that implements the specified interfaces * @throws IllegalArgumentException if any of the restrictions on the * parameters that may be passed to {@code getProxyClass} * are violated * @throws NullPointerException if the {@code interfaces} array * argument or any of its elements are {@code null}, or * if the invocation handler, {@code h}, is * {@code null} */ publicstatic Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) throws IllegalArgumentException { if (h == null) { thrownewNullPointerException(); }
/* * Look up or generate the designated proxy class. */ Class<?> cl = getProxyClass(loader, interfaces);
/** * Returns the {@code java.lang.Class} object for a proxy class * given a class loader and an array of interfaces. The proxy class * will be defined by the specified class loader and will implement * all of the supplied interfaces. If a proxy class for the same * permutation of interfaces has already been defined by the class * loader, then the existing proxy class will be returned; otherwise, * a proxy class for those interfaces will be generated dynamically * and defined by the class loader. * * <p>There are several restrictions on the parameters that may be * passed to {@code Proxy.getProxyClass}: * * <ul> * <li>All of the {@code Class} objects in the * {@code interfaces} array must represent interfaces, not * classes or primitive types. * * <li>No two elements in the {@code interfaces} array may * refer to identical {@code Class} objects. * * <li>All of the interface types must be visible by name through the * specified class loader. In other words, for class loader * {@code cl} and every interface {@code i}, the following * expression must be true: * <pre> * Class.forName(i.getName(), false, cl) == i * </pre> * * <li>All non-public interfaces must be in the same package; * otherwise, it would not be possible for the proxy class to * implement all of the interfaces, regardless of what package it is * defined in. * * <li>For any set of member methods of the specified interfaces * that have the same signature: * <ul> * <li>If the return type of any of the methods is a primitive * type or void, then all of the methods must have that same * return type. * <li>Otherwise, one of the methods must have a return type that * is assignable to all of the return types of the rest of the * methods. * </ul> * * <li>The resulting proxy class must not exceed any limits imposed * on classes by the virtual machine. For example, the VM may limit * the number of interfaces that a class may implement to 65535; in * that case, the size of the {@code interfaces} array must not * exceed 65535. * </ul> * * <p>If any of these restrictions are violated, * {@code Proxy.getProxyClass} will throw an * {@code IllegalArgumentException}. If the {@code interfaces} * array argument or any of its elements are {@code null}, a * {@code NullPointerException} will be thrown. * * <p>Note that the order of the specified proxy interfaces is * significant: two requests for a proxy class with the same combination * of interfaces but in a different order will result in two distinct * proxy classes. * * @param loader the class loader to define the proxy class * @param interfaces the list of interfaces for the proxy class * to implement * @return a proxy class that is defined in the specified class loader * and that implements the specified interfaces * @throws IllegalArgumentException if any of the restrictions on the * parameters that may be passed to {@code getProxyClass} * are violated * @throws NullPointerException if the {@code interfaces} array * argument or any of its elements are {@code null} */ //根据一组接口列表interfaces,返回一个由类加载器loader加载的实现了所有interfaces的类对象 //如果实现接口列表interfaces的类已经被加载过了;则直接返回缓存的类对象 publicstatic Class<?> getProxyClass(ClassLoader loader, Class<?>... interfaces) throws IllegalArgumentException { if (interfaces.length > 65535) { thrownewIllegalArgumentException("interface limit exceeded"); }
Class<?> proxyClass = null;
/* collect interface names to use as key for proxy class cache */ String[] interfaceNames = newString[interfaces.length];
// for detecting duplicates Set<Class<?>> interfaceSet = newHashSet<>();
//验证接口列表的接口对于参数给定的类加载器loader是否是可见的; //同时检查接口列表interfaces的合法性(无重复的接口、必须是接口类型) for (inti=0; i < interfaces.length; i++) { /* * Verify that the class loader resolves the name of this * interface to the same Class object. */ StringinterfaceName= interfaces[i].getName(); Class<?> interfaceClass = null; try { interfaceClass = Class.forName(interfaceName, false, loader); } catch (ClassNotFoundException e) { } if (interfaceClass != interfaces[i]) { thrownewIllegalArgumentException( interfaces[i] + " is not visible from class loader"); }
/* * Verify that the Class object actually represents an * interface. */ if (!interfaceClass.isInterface()) { thrownewIllegalArgumentException( interfaceClass.getName() + " is not an interface"); }
/* * Verify that this interface is not a duplicate. */ if (interfaceSet.contains(interfaceClass)) { thrownewIllegalArgumentException( "repeated interface: " + interfaceClass.getName()); } interfaceSet.add(interfaceClass);
interfaceNames[i] = interfaceName; }
/* * Using string representations of the proxy interfaces as * keys in the proxy class cache (instead of their Class * objects) is sufficient because we require the proxy * interfaces to be resolvable by name through the supplied * class loader, and it has the advantage that using a string * representation of a class makes for an implicit weak * reference to the class. */ List<String> key = Arrays.asList(interfaceNames);
/* * Find or create the proxy class cache for the class loader. */ Map<List<String>, Object> cache; synchronized (loaderToCache) { cache = loaderToCache.get(loader); if (cache == null) { cache = newHashMap<>(); loaderToCache.put(loader, cache); } /* * This mapping will remain valid for the duration of this * method, without further synchronization, because the mapping * will only be removed if the class loader becomes unreachable. */ }
/* * Look up the list of interfaces in the proxy class cache using * the key. This lookup will result in one of three possible * kinds of values: * null, if there is currently no proxy class for the list of * interfaces in the class loader, * the pendingGenerationMarker object, if a proxy class for the * list of interfaces is currently being generated, * or a weak reference to a Class object, if a proxy class for * the list of interfaces has already been generated. */ synchronized (cache) { /* * Note that we need not worry about reaping the cache for * entries with cleared weak references because if a proxy class * has been garbage collected, its class loader will have been * garbage collected as well, so the entire cache will be reaped * from the loaderToCache map. */ do { //cache 的key是接口名数组生成的list;value是一个代理类对象的弱引用 Objectvalue= cache.get(key); if (value instanceof Reference) { proxyClass = (Class<?>) ((Reference) value).get(); } if (proxyClass != null) { // proxy class already generated: return it return proxyClass; //如果是一个标志符号,则说明有另外的线程正在创建代理类;则该线程挂起等待 } elseif (value == pendingGenerationMarker) { // proxy class being generated: wait for it try { cache.wait(); } catch (InterruptedException e) { /* * The class generation that we are waiting for should * take a small, bounded time, so we can safely ignore * thread interrupts here. */ } continue;//被唤醒后;继续check是否存在类对象 } else { /* * No proxy class for this list of interfaces has been * generated or is being generated, so we will go and * generate it now. Mark it as pending generation. */ //不存在代理类的时候,需要自己去生成代理类;生成代理类之前先置一个状态标志对象pendingGenerationMarker cache.put(key, pendingGenerationMarker); break; } } while (true); }
try { StringproxyPkg=null; // package to define proxy class in
/* * Record the package of a non-public proxy interface so that the * proxy class will be defined in the same package. Verify that * all non-public proxy interfaces are in the same package. */ for (inti=0; i < interfaces.length; i++) { intflags= interfaces[i].getModifiers(); if (!Modifier.isPublic(flags)) { Stringname= interfaces[i].getName(); intn= name.lastIndexOf('.'); Stringpkg= ((n == -1) ? "" : name.substring(0, n + 1)); if (proxyPkg == null) { proxyPkg = pkg; } elseif (!pkg.equals(proxyPkg)) { thrownewIllegalArgumentException( "non-public interfaces from different packages"); } } }
if (proxyPkg == null) { // if no non-public proxy interfaces, proxyPkg = ""; // use the unnamed package }
{ /* * Choose a name for the proxy class to generate. */ long num; synchronized (nextUniqueNumberLock) { num = nextUniqueNumber++; } StringproxyName= proxyPkg + proxyClassNamePrefix + num; /* * Verify that the class loader hasn't already * defined a class with the chosen name. */
/* * Generate the specified proxy class. */ //重点在这里;调用ProxyGenerator的静态方法去生成一个代理类,得到类文件的字节数组 byte[] proxyClassFile = ProxyGenerator.generateProxyClass( proxyName, interfaces); try { //用类加载器加载二进制类文件,得到代理类对象 proxyClass = defineClass0(loader, proxyName, proxyClassFile, 0, proxyClassFile.length); } catch (ClassFormatError e) { /* * A ClassFormatError here means that (barring bugs in the * proxy class generation code) there was some other * invalid aspect of the arguments supplied to the proxy * class creation (such as virtual machine limitations * exceeded). */ thrownewIllegalArgumentException(e.toString()); } } // add to set of all generated proxy classes, for isProxyClass proxyClasses.put(proxyClass, null);
} finally { /* * We must clean up the "pending generation" state of the proxy * class cache entry somehow. If a proxy class was successfully * generated, store it in the cache (with a weak reference); * otherwise, remove the reserved entry. In all cases, notify * all waiters on reserved entries in this cache. */ synchronized (cache) { if (proxyClass != null) { //加入缓存 cache.put(key, newWeakReference<Class<?>>(proxyClass)); } else { cache.remove(key); } cache.notifyAll();//不管创建代理类是否成功,唤醒在cache上面等待的线程 } } return proxyClass; }
/** * Generate a class file for the proxy class. This method drives the * class file generation process. */ //根据得到的方法信息、类信息;按照JVM的规范动态的生成一个代理类的二进制文件 //该过程比较复杂涉及到许多JVM的指令 privatebyte[] generateClassFile() {
/* ============================================================ * Step 1: Assemble ProxyMethod objects for all methods to * generate proxy dispatching code for. */
/* * Record that proxy methods are needed for the hashCode, equals, * and toString methods of java.lang.Object. This is done before * the methods from the proxy interfaces so that the methods from * java.lang.Object take precedence over duplicate methods in the * proxy interfaces. */ addProxyMethod(hashCodeMethod, Object.class); addProxyMethod(equalsMethod, Object.class); addProxyMethod(toStringMethod, Object.class);
/* * Now record all of the methods from the proxy interfaces, giving * earlier interfaces precedence over later ones with duplicate * methods. */ for (inti=0; i < interfaces.length; i++) { Method[] methods = interfaces[i].getMethods(); for (intj=0; j < methods.length; j++) { addProxyMethod(methods[j], interfaces[i]); } }
/* * For each set of proxy methods with the same signature, * verify that the methods' return types are compatible. */ for (List<ProxyMethod> sigmethods : proxyMethods.values()) { checkReturnTypes(sigmethods); }
/* ============================================================ * Step 2: Assemble FieldInfo and MethodInfo structs for all of * fields and methods in the class we are generating. */ try { methods.add(generateConstructor());
for (List<ProxyMethod> sigmethods : proxyMethods.values()) { for (ProxyMethod pm : sigmethods) {
// add static field for method's Method object fields.add(newFieldInfo(pm.methodFieldName, "Ljava/lang/reflect/Method;", ACC_PRIVATE | ACC_STATIC));
// generate code for proxy method and add it methods.add(pm.generateMethod()); } }
if (methods.size() > 65535) { thrownewIllegalArgumentException("method limit exceeded"); } if (fields.size() > 65535) { thrownewIllegalArgumentException("field limit exceeded"); }
/* ============================================================ * Step 3: Write the final class file. */
/* * Make sure that constant pool indexes are reserved for the * following items before starting to write the final class file. */ cp.getClass(dotToSlash(className)); cp.getClass(superclassName); for (inti=0; i < interfaces.length; i++) { cp.getClass(dotToSlash(interfaces[i].getName())); }
/* * Disallow new constant pool additions beyond this point, since * we are about to write the final constant pool table. */ cp.setReadOnly();
try { /* * Write all the items of the "ClassFile" structure. * See JVMS section 4.1. */ // u4 magic; dout.writeInt(0xCAFEBABE); // u2 minor_version; dout.writeShort(CLASSFILE_MINOR_VERSION); // u2 major_version; dout.writeShort(CLASSFILE_MAJOR_VERSION);
cp.write(dout); // (write constant pool)
// u2 access_flags; dout.writeShort(ACC_PUBLIC | ACC_FINAL | ACC_SUPER); // u2 this_class; dout.writeShort(cp.getClass(dotToSlash(className))); // u2 super_class; dout.writeShort(cp.getClass(superclassName));
// u2 interfaces_count; dout.writeShort(interfaces.length); // u2 interfaces[interfaces_count]; for (inti=0; i < interfaces.length; i++) { dout.writeShort(cp.getClass( dotToSlash(interfaces[i].getName()))); }
// u2 fields_count; dout.writeShort(fields.size()); // field_info fields[fields_count]; for (FieldInfo f : fields) { f.write(dout); }
// u2 methods_count; dout.writeShort(methods.size()); // method_info methods[methods_count]; for (MethodInfo m : methods) { m.write(dout); }
// u2 attributes_count; dout.writeShort(0); // (no ClassFile attributes for proxy classes)
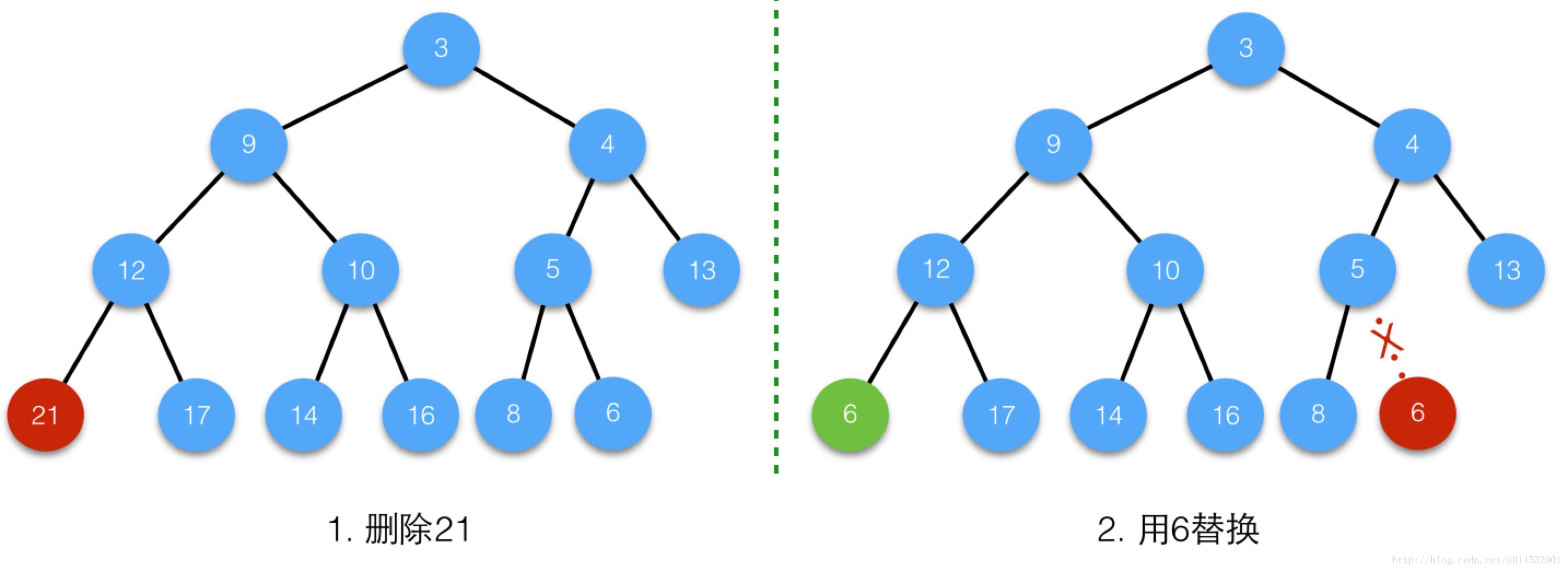
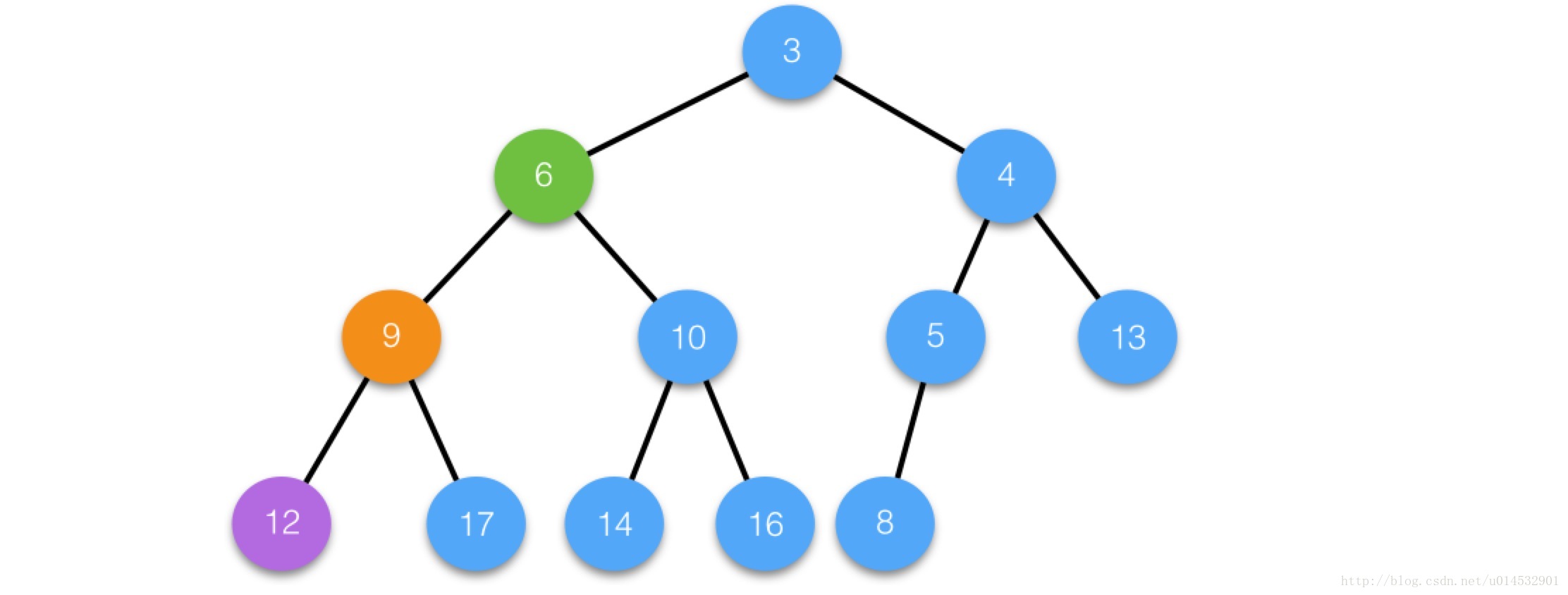
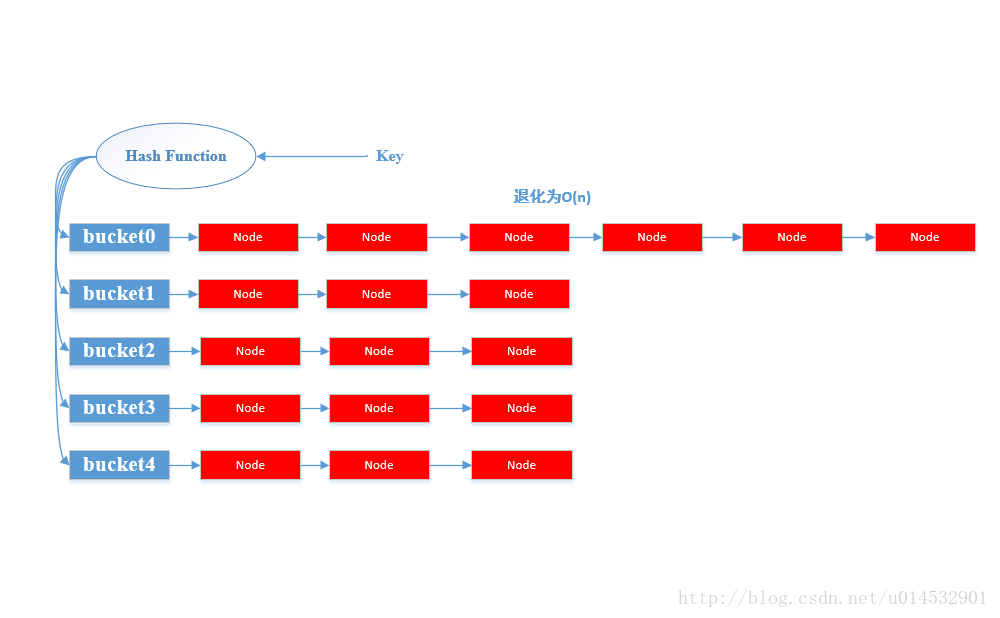
/** * Replaces all linked nodes in bin at index for given hash unless * table is too small, in which case resizes instead. */ finalvoidtreeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; //如果Hash表的桶数小于可以树形化的阈值,则只是扩大桶数,进行再Hash //我估计在设计的时候权衡了重建一颗红黑树和再Hash的cost,当桶的数量很少的时候,再hash划算一些 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); elseif ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { //从链表头hd,将每一个节点转化为一个树节点且继续保持链表的顺序 TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab);//最终树形化链表在这里完成 } }
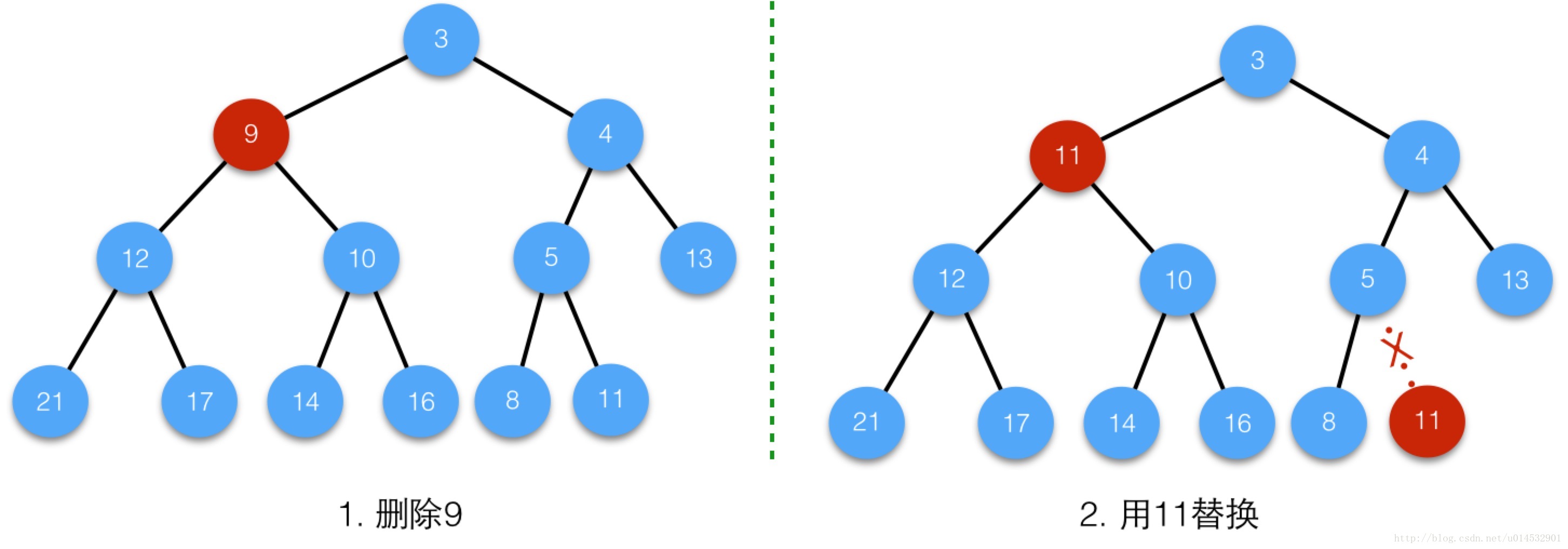
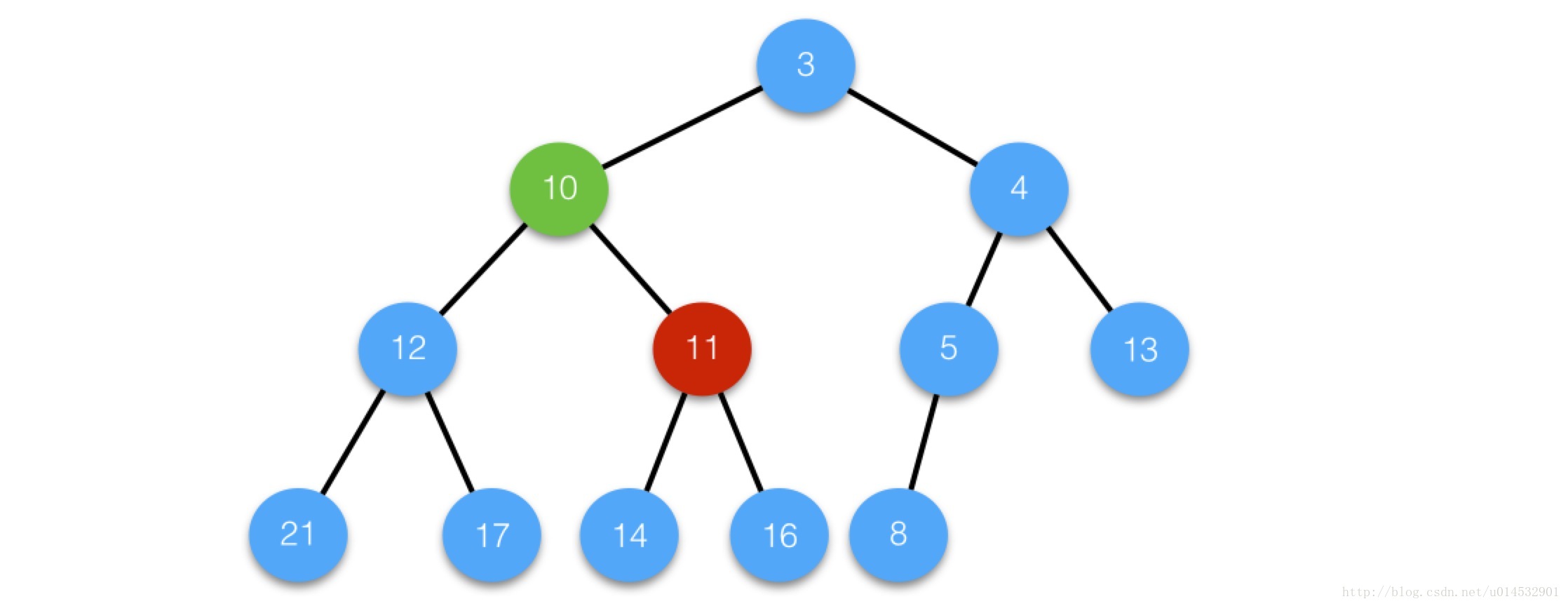
/** * Tie-breaking utility for ordering insertions when equal * hashCodes and non-comparable. We don't require a total * order, just a consistent insertion rule to maintain * equivalence across rebalancings. Tie-breaking further than * necessary simplifies testing a bit. */ staticinttieBreakOrder(Object a, Object b) { int d; if (a == null || b == null || (d = a.getClass().getName(). compareTo(b.getClass().getName())) == 0)//先利用两对象的类名的大小比较,若仍然陷入僵局,则调用 //System.identityHashCode()的方法该方法会返回对象唯一的真实的hash值无论对象的类是否重写了hashCode方法 d = (System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1); return d; }
/** * The head (eldest) of the doubly linked list. */ transient LinkedHashMap.Entry<K,V> head;//维护的双向链表的 /** * The tail (youngest) of the doubly linked list. */ transient LinkedHashMap.Entry<K,V> tail;//维护的双向链表的表尾
/** * The iteration ordering method for this linked hash map: <tt>true</tt> * for access-order, <tt>false</tt> for insertion-order. * * @serial */ finalboolean accessOrder;//是访问顺序还是插入顺序
主要关注以下几个方法:
1
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e)
//这个方法是HashMap的hook方法,只是简单的扩展了HashMap的Node类,就完成了LinkedHashMap的大部分功能 //不得不说类的设计很巧妙 Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = newLinkedHashMap.Entry<K,V>(hash, key, value, e);//将节点e linkNodeLast(p);//将该Entry链接到LinkedHashMap维护的双向链表的表尾 return p; }
1 2 3 4 5 6 7 8 9 10
/** * HashMap.Node subclass for normal LinkedHashMap entries. */ staticclassEntry<K,V> extendsHashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
1 2 3 4 5 6 7 8 9 10 11 12
// link at the end of list privatevoidlinkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail;//tail是维护的双链表的表尾 tail = p; //接下就是简单的链表链接操作 if (last == null) head = p; else { p.before = last; last.after = p; } }
abstractclassLinkedHashIterator { LinkedHashMap.Entry<K,V> next; LinkedHashMap.Entry<K,V> current; int expectedModCount;
LinkedHashIterator() { next = head;//head存放的是双向链表的表头 expectedModCount = modCount; current = null; }
publicfinalbooleanhasNext() { return next != null; }
final LinkedHashMap.Entry<K,V> nextNode() { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) thrownewConcurrentModificationException(); if (e == null) thrownewNoSuchElementException(); current = e; next = e.after;//依次迭代 return e; } }
/** * Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn * extends Node) so can be used as extension of either regular or * linked node. */ staticfinalclassTreeNode<K,V> extendsLinkedHashMap.Entry<K,V> {
for (m = 0; m < 9; m++) for (n = 0; n < 9; n++) if (board[m][n] != '.') { rowCount[m][board[m][n] - base] += 1; colCount[n][board[m][n] - base] += 1; subBoxCount[m / 3 * 3 + n / 3][board[m][n] - base] += 1; filledNum++; }
booleanfound=false; for (m = 0; m < 9; m++) {// 找到第一个待填的方格 for (n = 0; n < 9; n++) if (board[m][n] == '.') { found = true; break; } if (found) break; }
for (intnum=0; num < 9; num++) if (rowCount[m][num] == 0 && colCount[n][num] == 0 && subBoxCount[m / 3 * 3 + n / 3][num] == 0) if (dfs(m, n, (char) (num + base), board, rowCount, colCount, subBoxCount, filledNum)) break; }
publicbooleandfs(int i, int j, char c, char[][] board, int[][] rowCount, int[][] colCount, int[][] subBoxCount, int filledNum) {
intm= i, n = j; booleanfound=false; // 找到下一个待填方格 for (; m < 9; m++) { for (; n < 9; n++) { if (board[m][n] == '.') { found = true; break; } } if (found) break; else n = 0; }
for (intnum=0; num < 9; num++) { if (rowCount[m][num] == 0 && colCount[n][num] == 0 && subBoxCount[m / 3 * 3 + n / 3][num] == 0) { if (dfs(m, n, (char) (num + base), board, rowCount, colCount, subBoxCount, filledNum)) returntrue; } }