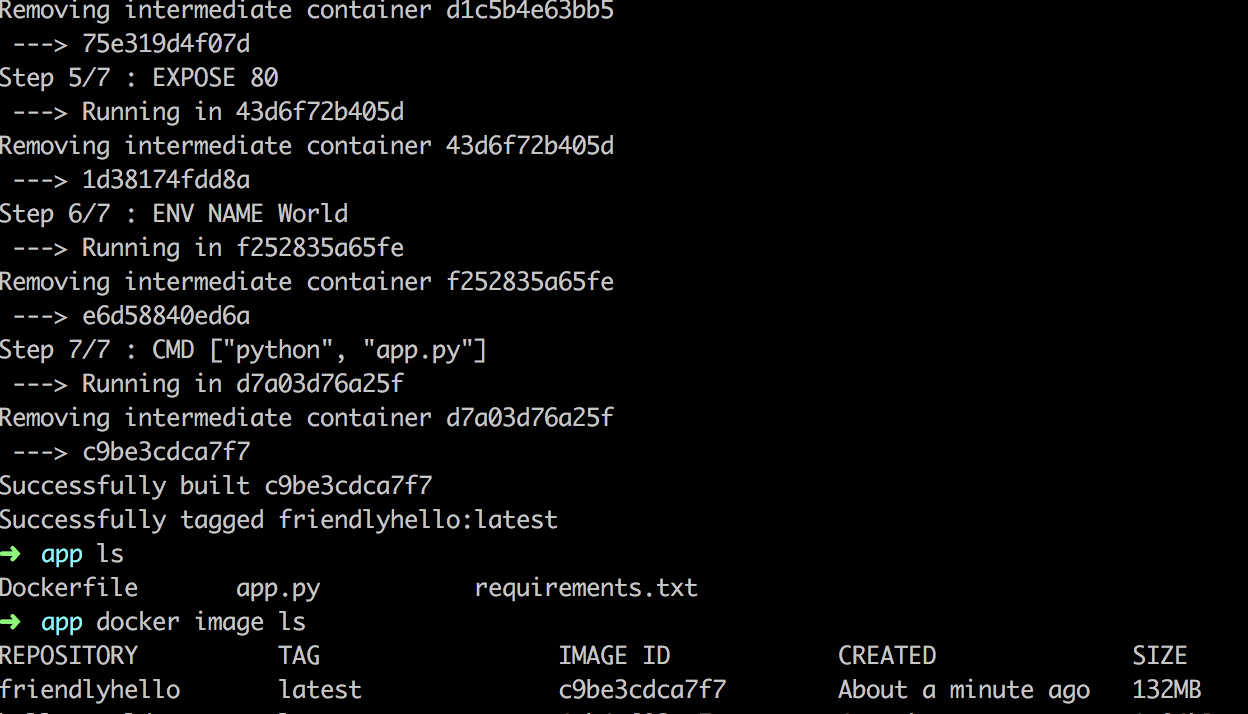
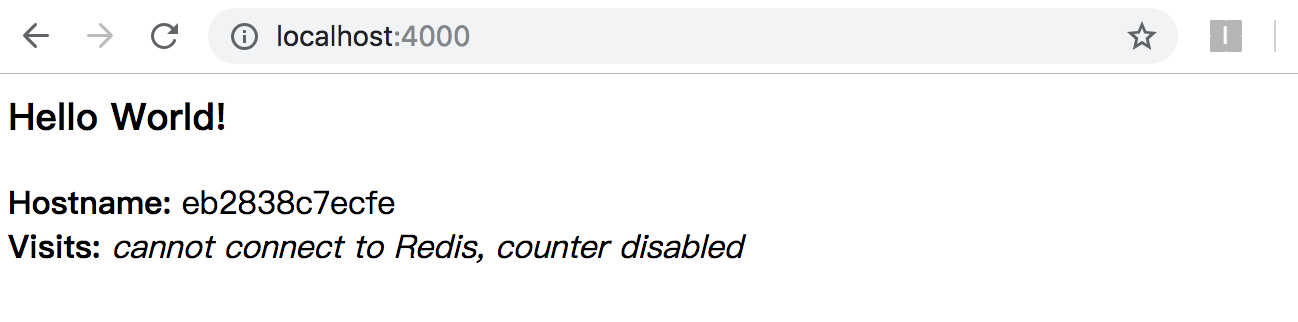
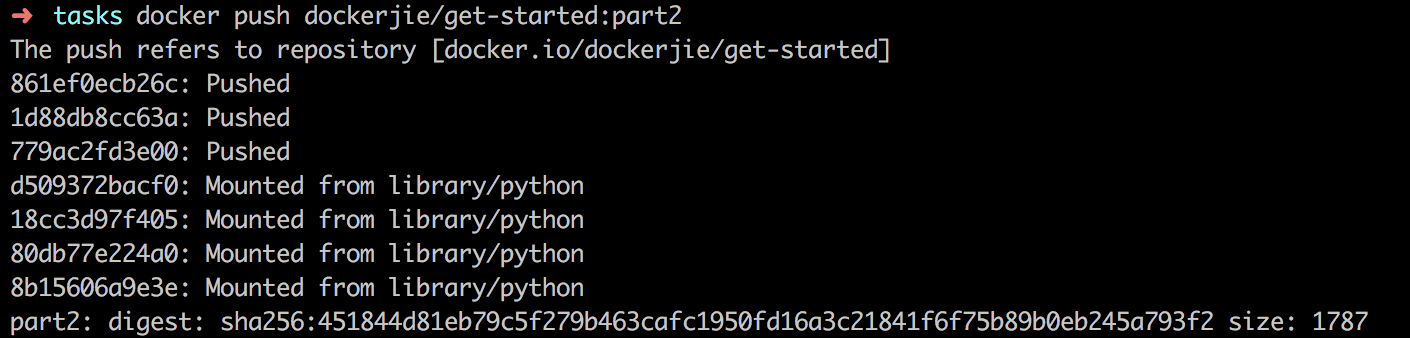
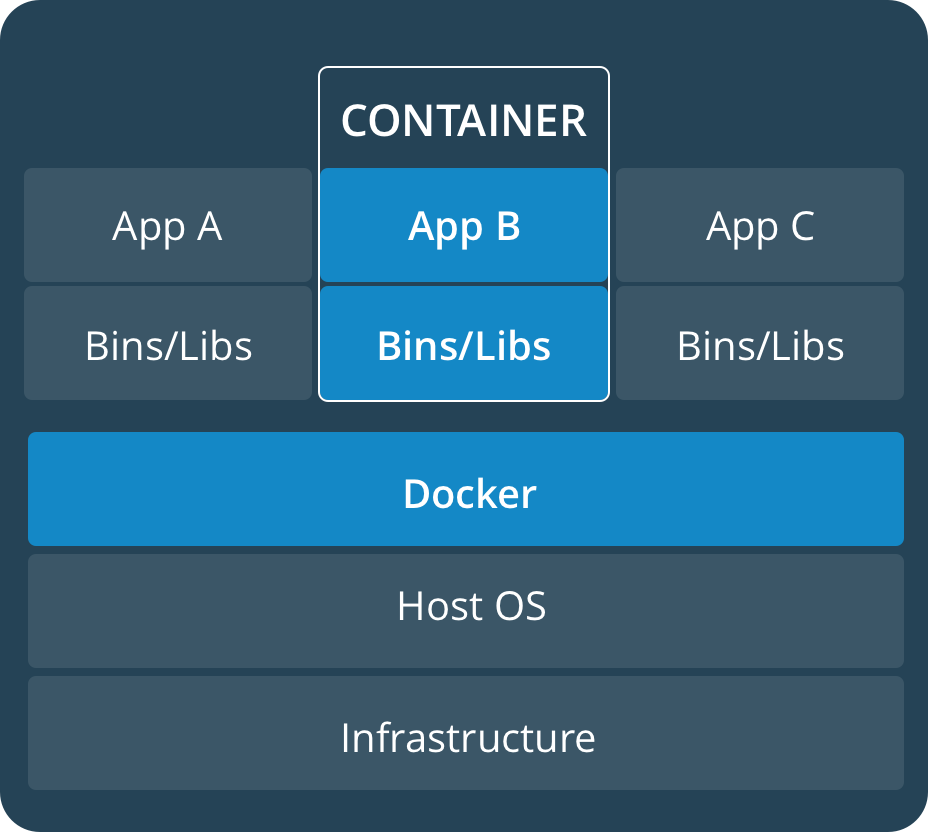
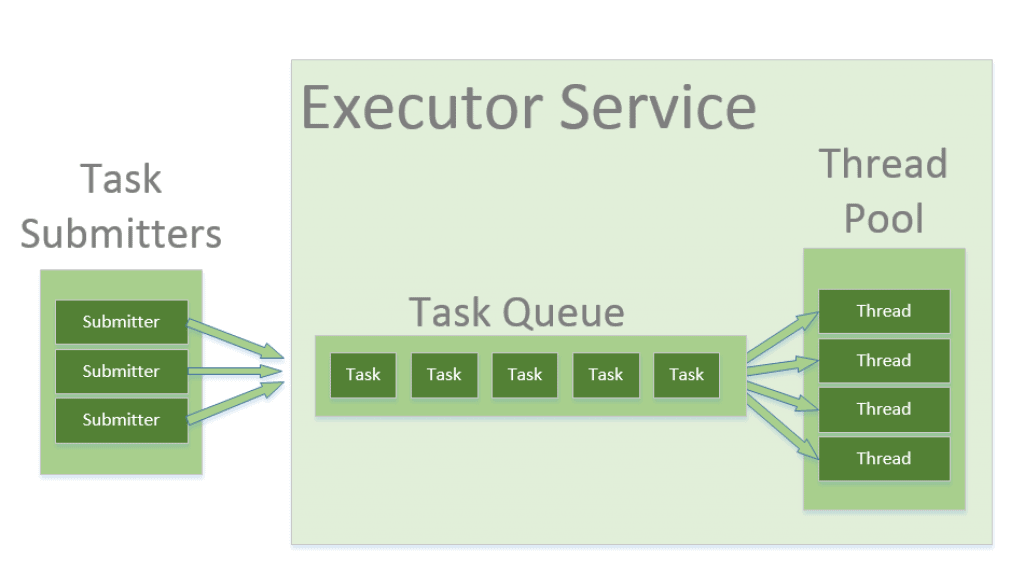
ChannelFuturefuture= bootStrap.bind(host, port).sync(); LOGGER.debug("server started on port {}", port);
// 注册服务 if (serviceRegistry != null) { serviceRegistry.register(serverAddress); } future.channel().closeFuture().sync(); } finally { LOGGER.debug("worker group and boss group shutdown"); workerGroup.shutdownGracefully(); bossGroup.shutdownGracefully(); } } }
a. 若前驱结点的右孩子为空,则将前驱结点的右孩子指向当前结点,当前结点更新为当前结点的左孩子;进入3;
b. 若前驱结点的右孩子为当前结点(不为空),将前驱结点的右孩子置NULL,输出当前结点,当前结点更新为当前结点的右孩子,进入3;
若当前结点不为空,进入1;否则程序结束;
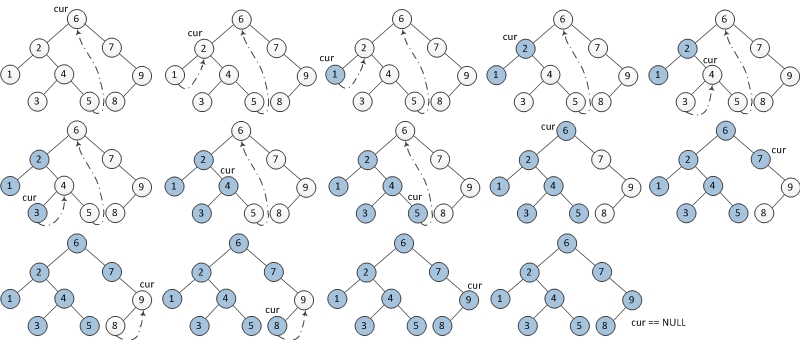
伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
cur = root repeat until cur != NULL: if cur.left != NULL: pre = cur.left; while pre.right == NULL && pre.right != cur://找到前驱结点pre pre = pre.right if pre.right == NULL: pre.right = cur cur = cur.left else: print(cur) pre.right = NULL cur = cur.right else: print(cur) cur = cur.right
publicstaticvoidinOrder(TreeNode root) { TreeNodecur= root, pre = null; for (; cur != null;) { if (cur.left != null) { pre = cur.left; // find predecessor while (pre.right != null && pre.right != cur) pre = pre.right; if (pre.right == null) {// create thread pre.right = cur; cur = cur.left; } else { print(cur); pre.right = null; cur = cur.right; } } else { print(cur); cur = cur.right; } } }
3. Morris 前序遍历
对于前序遍历,只需要在中序遍历的基础上稍加修改便可以完成。
Morris 前序遍历的流程如下:
当前结点的左孩子是否为空,若是则输出当前结点,并更新当前结点为当前结点的右孩子;否则进入2;
在当前结点的左子树中寻找中序遍历下的前驱结点(左子树中最右结点)
a. 若前驱结点的右孩子为空,则将前驱结点的右孩子指向当前结点,输出当前结点(在这里输出,和中序遍历不同的地方),当前结点更新为当前结点的左孩子;进入3;
b. 若前驱结点的右孩子为当前结点(不为空),将前驱结点的右孩子置NULL,当前结点更新为当前结点的右孩子,进入3;
若当前结点不为空,进入1;否则程序结束;
伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
cur = root; repeat until cur != NULL: if cur.left != NULL: pre = cur.left; while pre.right == NULL && pre.right != cur://找到前驱结点pre pre = pre.right if pre.right == NULL: pre.right = cur print(cur)//此处和中序遍历不同 cur = cur.left else: pre.right = NULL cur = cur.right else: print(cur) cur = cur.right
publicstaticvoidpreOrder(TreeNode root) { TreeNodecur= root, pre = null; for (;cur != null;) { if (cur.left != null) { pre = cur.left; // find predecessor while (pre.right != null && pre.right != cur) pre = pre.right; if (pre.right == null) {// create thread print(cur);// print node here pre.right = cur; cur = cur.left; } else { pre.right = null;//delete thread cur = cur.right; } } else { print(cur); cur = cur.right; } } }
4. Morris 后序遍历
后序遍历的流程如下:
新建一个Dummy结点,该结点的左孩子指向树根root,将Dummy作为当前结点;
当前结点的左孩子是否为空,更新当前结点为当前结点的右孩子;否则进入2;
在当前结点的左子树中寻找中序遍历下的前驱结点(左子树中最右结点):
a. 若前驱结点的右孩子为空,则将前驱结点的右孩子指向当前结点,当前结点更新为当前结点的左孩子,进入3;
b. 若前驱结点的右孩子为当前结点(不为空),反转当前结点到前驱结点之间的路径,输出该路径所有结点;反转当前结点到前驱结点之间的路径,恢复原状。将前驱结点的右孩子置NULL,当前结点更新为当前结点的右孩子,进入3;
若当前结点不为空,进入1;否则程序结束;
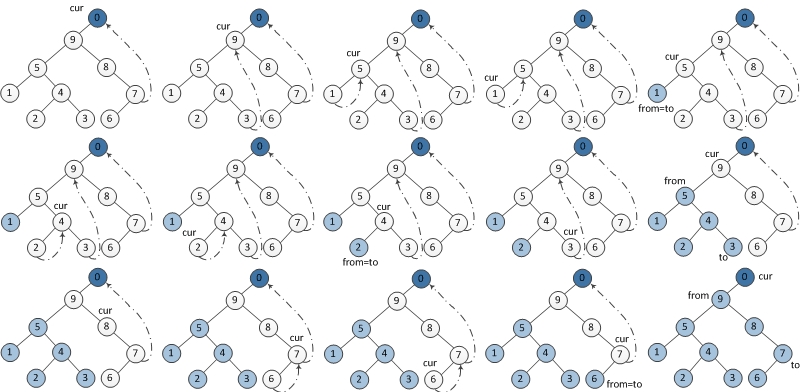
伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
dummy = Node(-1) dummy.left = root cur = dummy repeat until cur != NULL: if cur.left != NULL: pre = cur.left; while pre.right == NULL && pre.right != cur://找到前驱结点pre pre = pre.right if pre.right == NULL: pre.right = cur cur = cur.left else: reverse(cur.left, pre) print(pre, cur.left) reverse(pre, cur.left)//再次反转,恢复原状 pre.right = NULL cur = cur.right else: cur = cur.right
publicsynchronizedvoidstart() { .... try { start0(); started = true; } finally { try { if (!started) { group.threadStartFailed(this); } } catch (Throwable ignore) { /* do nothing. If start0 threw a Throwable then it will be passed up the call stack */ } } }
publicinterfaceCallable<V> { /** * Computes a result, or throws an exception if unable to do so. * * @return computed result * @throws Exception if unable to compute a result */ V call()throws Exception; }
@FunctionalInterface publicinterfaceRunnable { /** * When an object implementing interface <code>Runnable</code> is used * to create a thread, starting the thread causes the object's * <code>run</code> method to be called in that separately executing * thread. * <p> * The general contract of the method <code>run</code> is that it may * take any action whatsoever. * * @see java.lang.Thread#run() */ publicabstractvoidrun(); }
The isolation level that provides the least amount of protection between transactions. Queries employ a locking strategy that allows them to proceed in situations where they would normally wait for another transaction. However, this extra performance comes at the cost of less reliable results, including data that has been changed by other transactions and not committed yet (known as dirty read). Use this isolation level with great caution, and be aware that the results might not be consistent or reproducible, depending on what other transactions are doing at the same time. Typically, transactions with this isolation level only do queries, not insert, update, or delete operations.
The isolation level that uses the most conservative locking strategy, to prevent any other transactions from inserting or changing data that was read by this transaction, until it is finished. This way, the same query can be run over and over within a transaction, and be certain to retrieve the same set of results each time. Any attempt to change data that was committed by another transaction since the start of the current transaction, cause the current transaction to wait.
This is the default isolation level specified by the SQL standard. In practice, this degree of strictness is rarely needed, so the default isolation level for InnoDB is the next most strict, REPEATABLE READ.
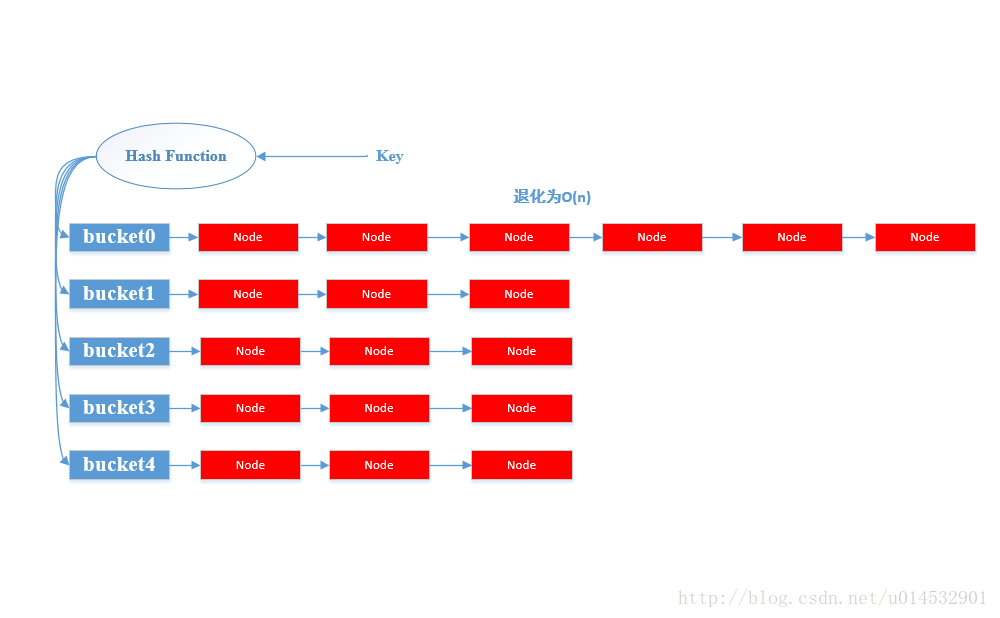
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ voidaddEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) {//当size大于等于某一个阈值thresholdde时候且该桶并不是一个空桶; /*这个这样说明比较好理解:因为size 已经大于等于阈值了,说明Entry数量较多,哈希冲突严重,那么若该Entry对应的桶不是一个空桶,这个Entry的加入必然会把原来的链表拉得更长,因此需要扩容;若对应的桶是一个空桶,那么此时没有必要扩容。*/ resize(2 * table.length);//将容量扩容为原来的2倍 hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length);//扩容后的,该hash值对应的新的桶位置 }
/** * Like addEntry except that this version is used when creating entries * as part of Map construction or "pseudo-construction" (cloning, * deserialization). This version needn't worry about resizing the table. * * Subclass overrides this to alter the behavior of HashMap(Map), * clone, and readObject. */ voidcreateEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = newEntry<>(hash, key, value, e);//链表的头插法插入新建的Entry size++;//更新size }
上面有几个重要成员变量:
size
threshold
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/** * The number of key-value mappings contained in this map. */ transientint size;
/** * The next size value at which to resize (capacity * load factor). * @serial */ int threshold;
/** * The load factor for the hash table. * * @serial */ finalfloat loadFactor;
/** * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically when the * number of keys in this map reaches its threshold. * * If current capacity is MAXIMUM_CAPACITY, this method does not * resize the map, but sets threshold to Integer.MAX_VALUE. * This has the effect of preventing future calls. * * @param newCapacity the new capacity, MUST be a power of two; * must be greater than current capacity unless current * capacity is MAXIMUM_CAPACITY (in which case value * is irrelevant). */ voidresize(int newCapacity) { Entry[] oldTable = table; intoldCapacity= oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) {//最大容量为 1 << 30 threshold = Integer.MAX_VALUE; return; }
/** * Retrieve object hash code and applies a supplemental hash function to the * result hash, which defends against poor quality hash functions. This is * critical because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. */ finalinthash(Object k) { inth=0; if (useAltHashing) { if (k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h = hashSeed; } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
This method acts as bridge between array-based and collection-based APIs, in combination with Collection.toArray. The returned list is serializable and implements RandomAccess.
Arrays.asList()
1 2 3 4 5
@SafeVarargs @SuppressWarnings("varargs") publicstatic <T> List<T> asList(T... a) { returnnewArrayList<>(a); }
ArrayList(E[] array) { a = Objects.requireNonNull(array); }
@Override publicintsize() { return a.length; }
@Override public Object[] toArray() { return a.clone(); }
@Override @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { intsize= size(); if (a.length < size) return Arrays.copyOf(this.a, size, (Class<? extendsT[]>) a.getClass()); System.arraycopy(this.a, 0, a, 0, size); if (a.length > size) a[size] = null; return a; }
@Override public E get(int index) { return a[index]; }
@Override public E set(int index, E element) { EoldValue= a[index]; a[index] = element; return oldValue; }
@Override publicintindexOf(Object o) { E[] a = this.a; if (o == null) { for (inti=0; i < a.length; i++) if (a[i] == null) return i; } else { for (inti=0; i < a.length; i++) if (o.equals(a[i])) return i; } return -1; }
public <T> T[] toArray(T[] a) { // Estimate size of array; be prepared to see more or fewer elements intsize= size(); T[] r = a.length >= size ? a : (T[])java.lang.reflect.Array .newInstance(a.getClass().getComponentType(), size);//如果给定的参数T[] a的长度足够存放当前collection(list or set)的元素,则采用该参数来存放元素;否则则根据参数给定的类型反射生成一个数组; //因此这里的参数T[] a有俩作用;第一:可能用作存放元素;第二:为返回数组提供类型 Iterator<E> it = iterator(); for (inti=0; i < r.length; i++) { if (! it.hasNext()) { // fewer elements than expected 集合的size少于给定的参数数组的长度 if (a == r) { r[i] = null; // null-terminate 最后一个元素被设置为null,表明collection元素结束; } elseif (a.length < i) { return Arrays.copyOf(r, i); } else { System.arraycopy(r, 0, a, 0, i); if (a.length > i) { a[i] = null; } } return a; } r[i] = (T)it.next(); } // more elements than expected return it.hasNext() ? finishToArray(r, it) : r; }