HashMap工作原理和扩容机制
1. HashMap工作原理
HashMap作为优秀的Java集合框架中的一个重要的成员,在很多编程场景下为我们所用。HashMap作为数据结构散列表的一种实现,就其工作原理来讲单独列出一篇博客来讲都是不过分的。由于本文主要是简单总结其扩容机制,因此对于HashMap的实现原理仅做简单的概述。
HashMap内部实现是一个桶数组,每个桶中存放着一个单链表的头结点。其中每个结点存储的是一个键值对整体(Entry),HashMap采用拉链法解决哈希冲突(关于哈希冲突后面会介绍)。
由于Java8对HashMap的某些地方进行了优化,以下的总结和源码分析都是基于Java7。
示意图如下:
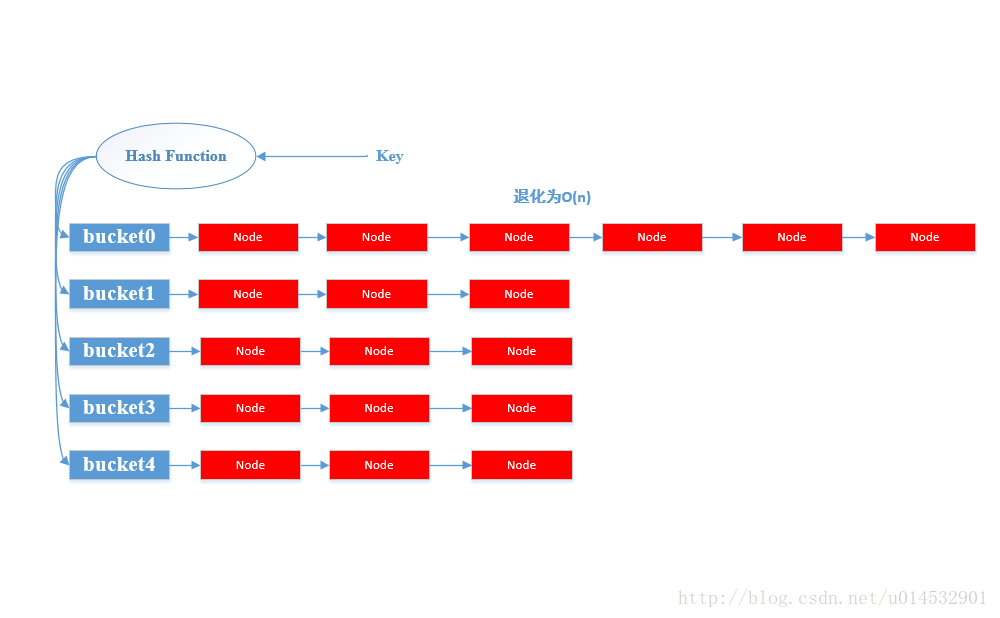
HashMap提供两个重要的基本操作,put(K, V)和get(K)。
- 当调用
put操作时,HashMap计算键值K的哈希值,然后将其对应到HashMap的某一个桶(bucket)上;此时找到以这个桶为头结点的一个单链表,然后顺序遍历该单链表找到某个节点的Entry中的Key是等于给定的参数K;若找到,则将其的old V替换为参数指定的V;否则直接在链表尾部插入一个新的Entry节点。 - 对于
get(K)操作类似于put操作,HashMap通过计算键的哈希值,先找到对应的桶,然后遍历桶存放的单链表通过比照Entry的键来找到对应的值。
以上就是HashMap的基本工作原理,但是问题总是比我们看到的要复杂。由于哈希是一种压缩映射,换句话说就是每一个Entry节点无法对应到一个只属于自己的桶,那么必然会存在多个Entry共用一个桶,拉成一条链表的情况,这种情况叫做哈希冲突。当哈希冲突产生严重的情况,某一个桶后面挂着的链表就会特别长,我们知道查找最怕看见的就是顺序查找,那几乎就是无脑查找。
哈希冲突无法完全避免,因此为了提高HashMap的性能,HashMap不得尽量缓解哈希冲突以缩短每个桶的外挂链表长度。
频繁产生哈希冲突最重要的原因就像是要存储的Entry太多,而桶不够,这和供不应求的矛盾类似。因此,当HashMap中的存储的Entry较多的时候,我们就要考虑增加桶的数量,这样对于后续要存储的Entry来讲,就会大大缓解哈希冲突。
因此就涉及到HashMap的扩容,上面算是回答了为什么扩容,那么什么时候扩容?扩容多少?怎么扩容?便是第二部分要总结的了。
2. HashMap扩容
2.1 HashMap的扩容时机
在使用HashMap的过程中,我们经常会遇到这样一个带参数的构造方法。
1 | public HashMap(int initialCapacity, float loadFactor) ; |
- 第一个参数:初始容量,指明初始的桶的个数;相当于桶数组的大小。
- 第二个参数:装载因子,是一个0-1之间的系数,根据它来确定需要扩容的阈值,默认值是0.75。
现在开始通过源码来寻找扩容的时机:
put(K, V)操作
1 | public V put(K key, V value) { |
既然找到一个空桶,那么新建的Entry必然会是这个桶外挂单链表的第一个结点。通过addEntry,找到了扩容的时机。
1 |
|
上面有几个重要成员变量:
- size
- threshold
1 | /** |
由注释可以知道:
size记录的是map中包含的Entry的数量
而threshold记录的是需要resize的阈值 且
threshold = loadFactor * capacitycapacity 其实就是桶的长度
1
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
因此现在总结出扩容的时机:
当map中包含的Entry的数量大于等于threshold = loadFactor * capacity的时候,且新建的Entry刚好落在一个非空的桶上,此刻触发扩容机制,将其容量扩大为2倍。(为什么2倍,而不是1.5倍,3倍,10倍;解释见最后的补充)
当size大于等于threshold的时候,并不一定会触发扩容机制,但是会很可能就触发扩容机制,只要有一个新建的Entry出现哈希冲突,则立刻resize。
直到这里我们回答了什么时候扩容和扩容多少的问题,那么下面回答如何扩容的问题。
2.2 HashMap的扩容过程
上面有一个很重要的方法,包含了几乎属于的扩容过程,这就是
1 | resize() |
1 | /** |
对于resize的过程,相对来讲是比较简单清晰易于理解的。旧桶数组中的某个桶的外挂单链表是通过头插法插入新桶数组中的,并且原链表中的Entry结点并不一定仍然在新桶数组的同一链表。
示意图如下:

这里很容易就想到多线程情况下,隐约感觉这个transfer方法在多线程环境下会乱套。事实上也是这样的,由于缺乏同步机制,当多个线程同时resize的时候,某个线程t所持有的引用next(参考上面代码next指向原桶数组中某个桶外挂单链表的下一个需要转移的Entry),可能已经被转移到了新桶数组中,那么最后该线程t实际上在对新的桶数组进行transfer操作。
如果有更多的线程出现这种情况,那很可能出现大量线程都在对新桶数组进行transfer,那么就会出现多个线程对同一链表无限进行链表反转的操作,极易造成死循环,数据丢失等等,因此HashMap不是线程安全的,考虑在多线程环境下使用并发工具包下的ConcurrentHashMap。
3. 补充
3.1 容量必须是2的幂
在resize(),为什么容量需要时2倍这样扩张,而不是1.5倍,3倍,10倍,另外在HashMap中有如下的代码:
1 | /** |
1 | public HashMap(int initialCapacity, float loadFactor) { |
通过以上我们知道HashMap的容量必须是2的幂,那么为什么要这么设计呢?答案当然是为了性能。在HashMap通过键的哈希值进行定位桶位置的时候,调用了一个indexFor(hash, table.length);方法。
1 | /** |
可以看到这里是将哈希值h与桶数组的length-1(实际上也是map的容量-1)进行了一个与操作得出了对应的桶的位置,h & (length-1)。
但是为什么不采用h % length这种计算方式呢?
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=4631373中提出Java的%、/操作比&慢10倍左右,因此采用&运算会提高性能。
**通过限制length是一个2的幂数,h & (length-1)和h % length结果是一致的。**这就是为什么要限制容量必须是一个2的幂的原因。
举个简单的例子说明这两个操作的结果一致性:
假设有个hashcode是311,对应的二进制是(1 0011 0111)
length为16,对应的二进制位(1 0000)
%操作:311 = 16*19 + 7;所以结果为7,二进制位(0111);&操作:(1 0011 0111) & (0111) = 0111 = 7, 二进制位(0111)1 0011 0111 = (1 0011 0000) + (0111) = (1*2^4 + 1* 2^5 + 0*2^6 + 0*2^7 + 1*2^8 ) + 7 = 2^4*(1 + 2 + 0 + 0 + 16) + 7 = 16 * 19 + 7; 和
%操作一致。如果
length是一个2的幂的数,那么length-1就会变成一个mask, 它会将hashcode低位取出来,hashcode的低位实际就是余数,和取余操作相比,与操作会将性能提升很多。
3.2 rehash
通过上面的分析可以看出,不同的键的的hashcode仅仅只能通过低位来区分。高位的信息没有被充分利用,举个例子:
假设容量为为16, 二进制位(10000)。
key1的hashcode为11111 10101,另一个key2的hashcode为00000 10101,很明显这两个hashcode不是一样的,甚至连相似性(例如海明距离)也是很远的。但是直接进行&操作得出的桶位置是同一个桶,这直接就产生了哈希冲突。
由于键的hashCode是HashMap的使用者来设计的,主要也就是我们这群程序员,由于设计一个良好的hashcode分布,是比较困难的,因此会容易出现分布质量差的hashcode分布,极端情况就是:所有的hashCode低位全相等,而高位不相等,这大大加大了哈希冲突,降低了HashMap的性能。
为了防止这种情况的出现,HashMap它使用一个supplemental hash function对键的hashCode再进行了一个supplemental hash ,将最终的hash值作为键的hash值来进行桶的位置映射(也就是说JDK团队在为我们这群程序员加性能保险Orz)。这个过程叫做再哈希(rehash)。
经过一个supplemental hash过程后,能保证海明距离为常数的不同的hashcode有一个哈希冲突次数上界(装载因子为0.75的时候,大约是8次)。
参见下段代码:
1 | /** |