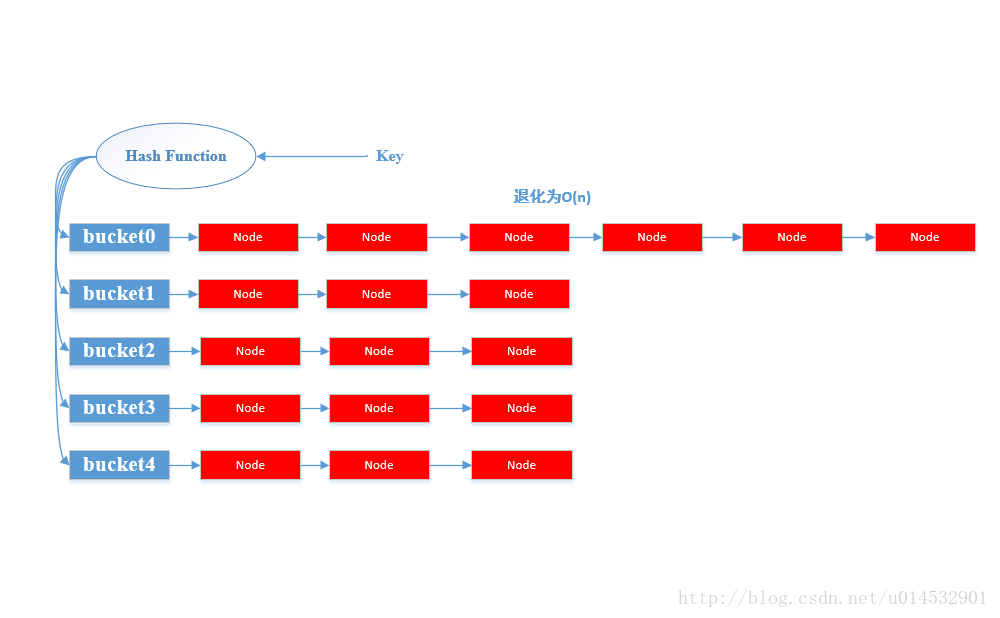
/** * Replaces all linked nodes in bin at index for given hash unless * table is too small, in which case resizes instead. */ finalvoidtreeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; //如果Hash表的桶数小于可以树形化的阈值,则只是扩大桶数,进行再Hash //我估计在设计的时候权衡了重建一颗红黑树和再Hash的cost,当桶的数量很少的时候,再hash划算一些 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); elseif ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { //从链表头hd,将每一个节点转化为一个树节点且继续保持链表的顺序 TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab);//最终树形化链表在这里完成 } }
/** * Tie-breaking utility for ordering insertions when equal * hashCodes and non-comparable. We don't require a total * order, just a consistent insertion rule to maintain * equivalence across rebalancings. Tie-breaking further than * necessary simplifies testing a bit. */ staticinttieBreakOrder(Object a, Object b) { int d; if (a == null || b == null || (d = a.getClass().getName(). compareTo(b.getClass().getName())) == 0)//先利用两对象的类名的大小比较,若仍然陷入僵局,则调用 //System.identityHashCode()的方法该方法会返回对象唯一的真实的hash值无论对象的类是否重写了hashCode方法 d = (System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1); return d; }
/** * The head (eldest) of the doubly linked list. */ transient LinkedHashMap.Entry<K,V> head;//维护的双向链表的 /** * The tail (youngest) of the doubly linked list. */ transient LinkedHashMap.Entry<K,V> tail;//维护的双向链表的表尾
/** * The iteration ordering method for this linked hash map: <tt>true</tt> * for access-order, <tt>false</tt> for insertion-order. * * @serial */ finalboolean accessOrder;//是访问顺序还是插入顺序
主要关注以下几个方法:
1
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e)
//这个方法是HashMap的hook方法,只是简单的扩展了HashMap的Node类,就完成了LinkedHashMap的大部分功能 //不得不说类的设计很巧妙 Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = newLinkedHashMap.Entry<K,V>(hash, key, value, e);//将节点e linkNodeLast(p);//将该Entry链接到LinkedHashMap维护的双向链表的表尾 return p; }
1 2 3 4 5 6 7 8 9 10
/** * HashMap.Node subclass for normal LinkedHashMap entries. */ staticclassEntry<K,V> extendsHashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
1 2 3 4 5 6 7 8 9 10 11 12
// link at the end of list privatevoidlinkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail;//tail是维护的双链表的表尾 tail = p; //接下就是简单的链表链接操作 if (last == null) head = p; else { p.before = last; last.after = p; } }
abstractclassLinkedHashIterator { LinkedHashMap.Entry<K,V> next; LinkedHashMap.Entry<K,V> current; int expectedModCount;
LinkedHashIterator() { next = head;//head存放的是双向链表的表头 expectedModCount = modCount; current = null; }
publicfinalbooleanhasNext() { return next != null; }
final LinkedHashMap.Entry<K,V> nextNode() { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) thrownewConcurrentModificationException(); if (e == null) thrownewNoSuchElementException(); current = e; next = e.after;//依次迭代 return e; } }
/** * Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn * extends Node) so can be used as extension of either regular or * linked node. */ staticfinalclassTreeNode<K,V> extendsLinkedHashMap.Entry<K,V> {